Installing and Administering Elasticsearch and OpenSearch
Overview
This guide will introduce administrators of on-site Sugar instances to the Elasticsearch and Amazon OpenSearch technology and provide some guidelines for installing and administering it for use with Sugar.
Note: SugarCRM does not support the installation and configuration of stack components such as Elasticsearch.
Elasticsearch
New technologies have emerged which scale and perform better than classic database (DB) systems for statistical analysis, full-text search, and result faceting. Since Sugar 6.5, Elasticsearch (ES) was introduced as an optional system to power the global search functionality. ES capabilities have improved and so has its integration with Sugar. Because it is no longer possible to maintain DB-only fallback scenarios for the more advanced functionality in Sugar, ES is now a required component. Because of this, you can expect more advanced search functionality in upcoming releases.
Please note that Sugar will keep partial information from the DB in sync with ES. At any given point, the information contained in ES can be rebuilt from scratch. This is what we refer to as "performing a full re-index".
How Does It Work?
All Sugar data is primarily stored in the database of your choice. Additional logic inside the Sugar code base will also store partial data inside ES. For general search functionality, Sugar will use the ES capabilities to retrieve data instead of using the DB server. This results in faster, more detailed, and more relevant results for a better user experience.
Is the Classic DB Going Away?
Not at all! Both technologies complement each other. ES primarily targets flexible, complex searches at lightning speed combined with easy scalability. Although some classic Relational Database Models (RDBMs) have certain functionalities for full-text search, those possibilities have more limitations and are not easy to maintain or scale for larger systems.
Integrating with Sugar
By default, the installation and upgrade process will create just one index to store all the documents for every full-text search enabled module. The name of the index is the same as the unique instance ID which was created during installation (see the config.php file for your Sugar instance).
During index creation, Sugar will automatically deploy the necessary mappings for every module and queue all available records inside the fts_queue table. As mentioned above, the execution of Sugar cron is responsible for processing (consuming) the queue. Depending on the data size, the full re-index process can take anywhere from a few minutes to a few hours.
Note: For very large datasets, it is advised to avoid full re-index operations unless absolutely necessary.
Every SugarBean::save() call will automatically trigger an update of the ES data to sync up with the DB for potential changes. However, if for any reason ES is not available, changes will be queued inside the fts_queue table. The processing of these queued items is then handled by cron execution. For more information about setting up the cron scheduler, please refer to the Schedulers documentation.
Note: There is a manual configuration option to force the usage of the fts_queue table in case the inline ES updates are slowing down the system, which means there may be some data inconsistency between the DB and ES until cron catches up with the queued items from the fts_queue table. For more information, please see the Basic Configuration section below.
Deployment Overview
There are several different deployment options for the three main components:
- Web Server
- Database (DB) Server
- Elasticsearch (Elastic) Server
For smaller installations, all three components can run on the same server. However, when an instance grows larger, it is easy to scale up by just moving the DB and ES server to dedicated machines. 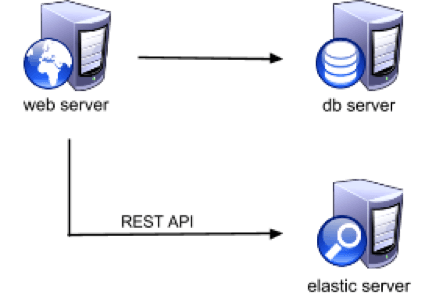
Network Communication
Please refer to the Configuring IP Addresses, Ports, and Domains article information on the ports used by default.
Security
End users and other applications should not be able to connect directly to the ES server. It is strongly advised to put your ES server(s) in a separate security zone and only allow your web server(s) to connect to the ES server(s).
The following settings should be configured in elasticsearch.yml in order to increase ES security:
action.destructive_requires_name: true
Note: If you have an ES cluster, all cluster members need to be able to talk to each other via TCP port 9300. ES does NOT support out-of-the-box SSL/TLS secured connections for both API and node-to-node connections and does NOT perform any user authentication. Therefore, it is very important to shield off the access to your ES cluster.
Sizing
As with all systems, it is always difficult to predict the actual usage and load. ES is very powerful and scales very easily. When ES starts to slow down, it is very easy just to add a new node. This does not require much planning or configuration in advance for the average Sugar installation when following the basic guidelines in this manual. This basically means that you can safely start a deployment on a basic ES setup and scale up easily based on recommendations below. Please refer to the Monitoring and Maintenance section below how to monitor key metrics before deciding to expand your cluster.
Note: There may be some consequences for certain settings, but those only apply to instances that have millions of objects spanned across a multitude of different Web Servers and DB nodes.
Clusters
It is advised to set up at least a three-node ES cluster for production systems, primarily for fault tolerance and secondarily for performance distribution. The odd number of master nodes in the Elasticsearch cluster is to avoid a split brain problem. As stated above, ES data can be rebuilt at any given time from scratch in case of a drastic cluster configuration change or during disaster recovery.
ES supports running more than one node on the same physical or virtual machine, although this is not recommended for production environments. When using such an environment, ES will automatically assign different port numbers (i.e. 9201, 9301, etc.) for additional nodes.
Sizing Nodes
Data size
On average, the actual size on disk should not exceed twice the database size. Sugar only stores a subset of the actual DB data into ES and only for specific modules. Adding more fields (through Studio and/or vardefs) to the search index will increase the disk usage. Data size also varies depending on additional customizations and the complexity of the security model.
Note: If you want a screaming fast ES installation, consider using SSD drives, although this is definitely not a requirement.
Memory
ES makes use of heavy caching on different levels to achieve its performance. When assigning memory to ES, it is advised to never exceed half of the total amount of available memory of the system and even less if not using a dedicated ES node (see the System Configuration section below). This will preserve enough available memory for the operating system file system cache, which will speed up disk access.
It is also not recommended to have more than 30GB of RAM in the ES heap size so the Java Virtual Machine (JVM) is able to apply pointer compression, which mostly results in higher performance. This has to do with how a JVM implements its functionality on 64-bit platforms, although its implementation can vary between the different Java providers. In general, ES will perform better with configurations having more nodes with smaller memory footprints than those with fewer nodes with very big heap sizes.
Connections
ES automatically balances requests, both index and search operations, amongst the different cluster members. However, the amount of simultaneous connections towards the cluster is not infinite and depends on concurrent usage. For the average Sugar installation, this will not be a concern as long as the file descriptor limit is set to at least 64K.
Example
Assume the following Sugar environment:
- Sugar Professional
- 100 users, 25 simultaneous
- DB size is 2 GBytes using MySQL
Minimum setup:
- ES cluster with one node
- 2GB RAM, 1GB dedicated to ES
- Targeted 4 GBytes of disk storage for ES
Recommended setup:
- ES cluster with three nodes
- 4GB RAM, 2GB dedicated to ES
- Targeted 4 GBytes of disk storage for ES
Note: The recommendation above is just a general guideline and the actual sizing may vary depending on your environment. It is highly recommended to monitor the key metrics as explained in the Monitoring and Maintenance section below.
Installing Elasticsearch
ES is available for all major Unix and Windows platforms. ES can be installed using different formats from the Elasticsearch website, compiled from the source manually, or by using your Linux distro depending on availability.
Another possibility is to make use of our pre-configured ES appliance. This is a generic ES appliance and not specifically tweaked for a Sugar deployment. However, this is a good starting point during development or initial ES setup. There are also different formats are available for this appliance (VMWare, HyperV, KVM, OVF, direct deploy on AWS /Azure, etc.).
For information about which versions of Elasticsearch are supported for your Sugar installation, please refer to the Supported Platforms page specific to your Sugar version.
Note: SugarCRM does not support the installation and configuration of stack components such as Elasticsearch.
Red Tape
ES is built on top of Apache Lucene and both require Java. It is absolutely essential to make sure that all ES nodes use exactly the same Java version and the same ES version. When upgrading ES, it is worth considering to upgrade the Java environment too. Cluster instability is primarily caused by using older Java versions or out of sync versions across the cluster members.
Java
Install the same Java version (exact match on major/minor version) on every ES node. Make sure that you use the latest stable and supported version of the Java platform. Internally our testing and validation are done with the OpenJDK which is free to use.
System Configuration
Make sure your system is configured with at least a 32K open file descriptor limit, although 64K is recommended. There are system-wide or user-level limits that can be configured. Please refer to the following article for more details on how to set and verify the file descriptor limit: http://www.cyberciti.biz/faq/linux-increase-the-maximum-number-of-open-files/
It is highly recommended to add additional command line options when starting the ES process to log the available file descriptors during startup:
-Des.max-open-files=true
The output in the log file will look like this:
[2013-12-13 17:54:40,716][INFO ][bootstrap] max_open_files [65510]
[2013-12-13 17:54:41,315][INFO ][node ] [Amanda Sefton] version[0.90.7], pid[5853]
[2013-12-13 17:54:41,315][INFO ][node ] [Amanda Sefton] initializing ...
[2013-12-13 17:54:41,324][INFO ][plugins ] [Amanda Sefton] loaded [], sites []
[2013-12-13 17:54:45,666][INFO ][node ] [Amanda Sefton] initialized
[2013-12-13 17:54:45,666][INFO ][node ] [Amanda Sefton] starting ...
ES Configuration
/etc/elasticsearch/elasticsearch.yml
The main configuration file is called elasticsearch.yml and is by default installed under ./etc/elasticsearch when using the RPM installer. This file contains a detailed explanation of the available settings.
The following is a list of minimum recommended configuration parameters:
- cluster.name : This is the name of your cluster and should be the same for all nodes.
cluster.name: sugarcrm - node.name : Every node should have a unique name.
node.name: your_node_name_here - bootstrap.memory_lock : This will lock to memory and prevent swapping. Use with caution when in combination with the configured heap size.
bootstrap.memory_lock: true
Note: The bootstrap.memory_lock configuration was named bootstrap.mlockall in versions lower than Elasticsearch 5.x. For more information, please refer to the Elasticsearch documentation.
The majority of these parameters can also be altered using the API itself. Sugar has the ability to alter index specific settings using $sugar_config without the need to alter the node configuration file directly.
/etc/sysconfig/elasticsearch
This additional file contains settings which are used by the startup script, using RPM install.
ES_HEAP_SIZE=8g
This sets the amount of memory to allocate to ES.
ES_JAVA_OPTS="-Des.max-open-files=true"
Additional startup parameters, that shows the actual open files limit during startup as mentioned above.
MAX_OPEN_FILES=65535
This should match the file descriptor limit.
MAX_LOCKED_MEMORY=unlimited
This should be set to unlimited (see mlockall above).
Configuring Sugar
Basic Configuration
The following are the basic parameters supported in $sugar_config (config_override.php):
'full_text_engine' => array (
'Elastic' => array (
'host' => '127.0.0.1',
'port' => '9200',
),
),
There is an optional parameter to force the manual usage of fts_queue (asynchronous mode).
Note: Sugar cron is responsible to process the queued records. Therefore, there will be a slight delay between record updates in the DB and updates in ES.
$sugar_config['search_engine']['force_async_index'] = true;
Advanced Configuration
Additional connection parameters can be supplied which are not exposed in the UI. This has been done to support non-standard setups. The following parameters are passed to the Elastica backend "as is".
The following settings are supported for Sugar versions 14.0.0 and higher.
['full_text_engine']['Elastic']['transport']
['full_text_engine']['Elastic']['username']
['full_text_engine']['Elastic']['password']
This is the transport mechanism to use when trying to connect to the Elasticsearch cluster. Possible values are: Http (default), Https, Thrift and Memcache.
['full_text_engine']['Elastic']['curl'] = array()
This array can be used to pass additional curl parameters into the Http or Https transport mechanism (see http://php.net/curl_setopt).
For example, having a reverse proxy sitting in between the SugarCRM web server and the Elasticsearch cluster which requires an SSL connection and username/password authentication, the following settings can be used:
$sugar_config['full_text_engine']['Elastic']['host'] = 'my.proxy.com';
$sugar_config['full_text_engine']['Elastic']['port'] = '8888';
$sugar_config['full_text_engine']['Elastic']['transport'] = 'Https';
$sugar_config['full_text_engine']['Elastic']['curl'][CURLOPT_USERPWD] = 'user:password';
$sugar_config['full_text_engine']['Elastic']['curl'][CURLOPT_SSL_VERIFYPEER] = false;
Advanced Index Settings
Additional parameters can be passed to ES on index creation. Please consult the ES Documentation to understand the different parameters. For example, to set the number of shards, the following can be configured:
$sugar_config['full_text_engine']['Elastic']
['index_settings']['default']['index.number_of_shards'] = 4;
Advanced Index Routing
By default, Sugar uses only one index for the whole system (Single Index Strategy). However, there is also an experimental "multi-index" approach, which is only configurable in the config_override.php file.
Monitoring and Maintenance
Tools
ES does not have out-of-the-box tools which can be used to monitor and maintain an ES cluster. However, there are some nice tools available for free which can be easily installed as ES plug-ins and are all web-based.
Here is a list of plugins which may come in handy:
- Marvel, from the Elasticsearch website, is an official ES tool, only free for development.
- Head provides a quick Elasticsearch cluster overview that is very useful during development and testing.
- Bigdesk provides detailed monitoring of your ES cluster with live update graphs.
- Segment Spy shows visualizations of different Lucene segments.
Note: The links above all contain examples of how to install the plugins on the CLI.
Key Metrics
It is important to monitor some key metrics of your ES cluster. You can use the Bigdesk plugin or make use of the API _cluster/_index status calls to obtain and monitor the following information:
- Memory Usage
- Field Data Cache (mostly depends on the number of facets)
- HTTP Connections
- Open Files
- Disk Space
Amazon OpenSearch
OpenSearch (supported for Sugar versions 14.0 and higher) is an open-source search and analytics engine introduced by Amazon as an alternative to Elasticsearch. OpenSearch can be used both locally (on-site) and through Amazon’s managed services, offering flexibility in how you deploy and scale your search infrastructure. For more information on OpenSearch, refer to the What is OpenSearch? page on the AWS site.
Using Amazon OpenSearch
If you wish to use Amazon OpenSearch, refer to the Getting started with Amazon OpenSearch Service page on the AWS site for information on how to set up OpenSearch. For more information regarding storage requirements for OpenSearch and how it is calculated, refer to the Calculating storage requirements page.