Elastic Search
Overview
The focus of this document is to guide developers on how Sugar integrates with Elastic Search.
Resources
We recommend the following resources to get started with Elasticsearch:
Deployment
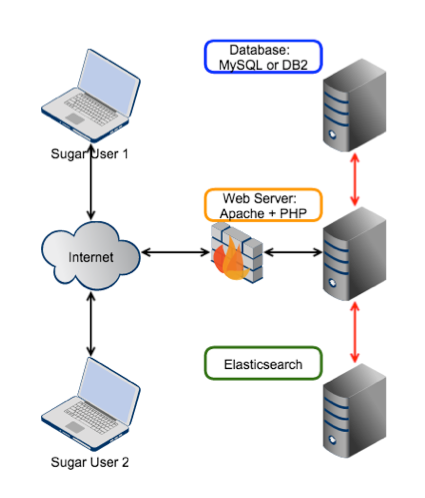
The following figure shows a typical topology of Elasticsearch with a Sugar system. All the communication with Elasticsearch goes through Sugar via REST APIs.
Framework
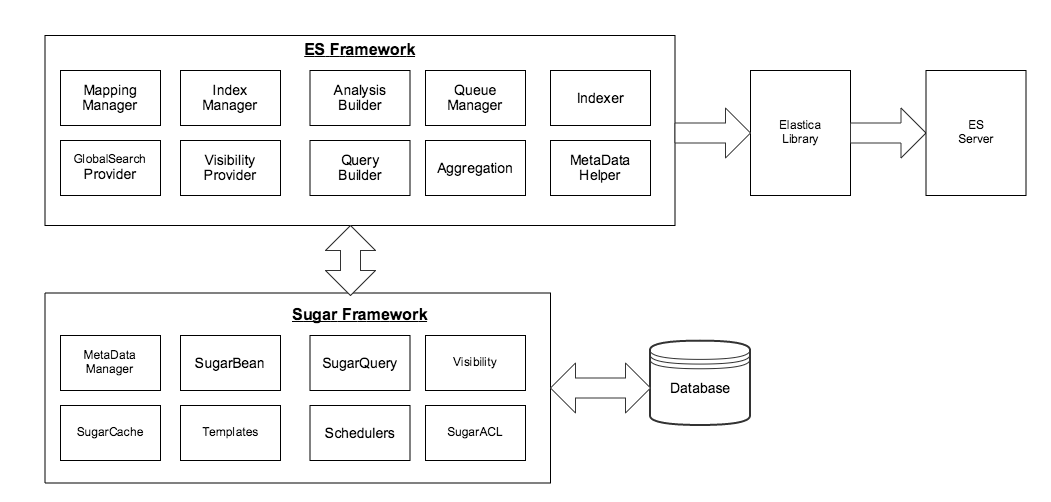
The following figure shows the overall architecture with main components in the Elasticsearch framework and related components in Sugar framework.
Main Components
This section describes how to use each of the main components in detail.
Mapping Manager
This component builds the mappings for providers in the system. The mappings are used for Elastic to interpret data stored there, which is similar to a database schema.
- Define the
full_text_searchproperty in a module's vardef file for a given field:
- enabled : sets the field to be enabled for global search;
- searchable : sets the field to be searchable or not;
- boost : sets the boost value so that the field can be ranked differently at search time.
- type : overrides the sugar type originally defined;
- aggregations : sets the properties specific related to aggregations;
- Define what analyzers to use for a given sugar type:
- The analyzers for both indexing and searching are specified. They may be different for the same field. The index analyzer is used at indexing time, while the search analyzer is used at query time.
- Each of the providers generates its own mapping.
- Generates mappings for each field and sends it over to Elasticsearch.
Example Mapping
This section outlines how the mapping is created for Account module's name field. The Account module's name field is defined as "searchable" in the "full_text_search" index of the vardefs. The Sugar type "name" uses the regular and ngram string analyzers for indexing and search.
./modules/Accounts/vardefs.php
...
'name' => array(
'name' => 'name',
'type' => 'name',
'dbType' => 'varchar',
'vname' => 'LBL_NAME',
'len' => 150,
'comment' => 'Name of the Company',
'unified_search' => true,
'full_text_search' => array(
'enabled' => true,
'searchable' => true,
'boost' => 1.9099999999999999,
),
'audited' => true,
'required' => true,
'importable' => 'required',
'duplicate_on_record_copy' => 'always',
'merge_filter' => 'selected',
),
...
The field handler, located in ./src/Elasticsearch/Provider/GlobalSearch/Handler/Implement/MultiFieldHandler.php, defines the mappings used by Elasticsearch. The class property $typesMultiField in the MultiFieldHandler class defines the relationship between types and mappings. For the "name" type, we use the gs_string and gs_string_wildcard definitions to define our mappings and analyzers.
./src/Elasticsearch/Provider/GlobalSearch/Handler/Implement/MultiFieldHandler.php
...
protected $typesMultiField = array(
...
'name' => array(
'gs_string',
'gs_string_wildcard',
),
...
);
...
The class property $multiFieldDefs in the MultiFieldHandler class defines the actual Elasticsearch mapping to be used.
...
protected $multiFieldDefs = [
...
/*
* Default string analyzer with full word matching base ond
* the standard analyzer. This will generate hits on the full
* words tokenized by the standard analyzer.
*/
'gs_string' => [
'type' => 'text',
'index' => true,
'analyzer' => 'gs_analyzer_string',
'store' => true,
],
/*
* String analyzer using ngrams for wildcard matching. The
* weighting of the hits on this mapping are less than full
* matches using the default string mapping.
*/
'gs_string_wildcard' => [
'type' => 'text',
'index' => true,
'analyzer' => 'gs_analyzer_string_ngram',
'search_analyzer' => 'gs_analyzer_string',
'store' => true,
],
...
];
...
The mapping is created from the definitions in Elasticsearch. A sample mapping is shown below:
"Accounts__name": {
"include_in_all": false,
"index": "not_analyzed",
"type": "string",
"fields":{
"gs_string_wildcard":{
"index_analyzer": "gs_analyzer_string_ngram",
"store": true,
"search_analyzer": "gs_analyzer_string",
"type": "string"
},
"gs_string":{
"store": true,
"analyzer": "gs_analyzer_string",
"type": "string"
}
}
}
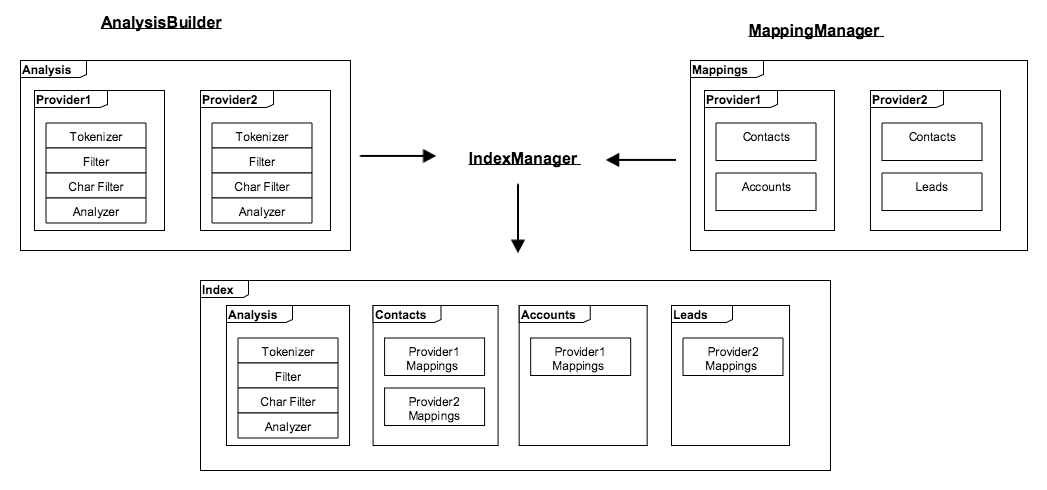
Index Manager
An index includes types, similar to a database including tables. In our system, a type is based on a module consisting of mappings.
As shown in the following figure, the Index Manager combines the analysis built from Analysis Builder and the mappings from Mapping Manager from different providers and organizes them by modules.
Indexer & Queue Manager
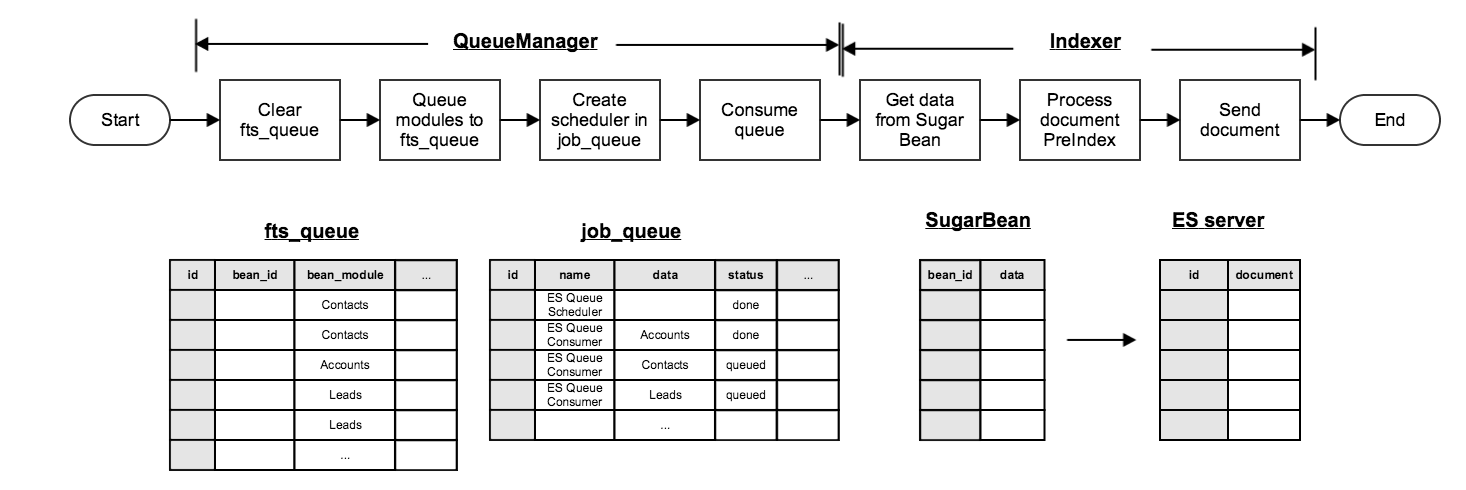
After creating the index, data needs to be moved from the Sugar system to Elasticsearch. The queue manager uses the fts_queue and job_queue tables to queue the information. The indexer then processes data from Sugar bean into the format of Elasticsearch documents.
The whole process is as follows:
- Each Sugar bean is added to
fts_queuetable. - Elasticsearch queue scheduler is added to
job_queuetable. - When the job starts, the scheduler generates an Elasticsearch queue consumer for each module.
- Each consumer queries the
fts_queuetable fo find the corresponding sugar beans. - The indexer gets fields from each bean and processes them into individual documents.
- The indexer uses the bulk APIs to send documents to Elasticsearch in batches.
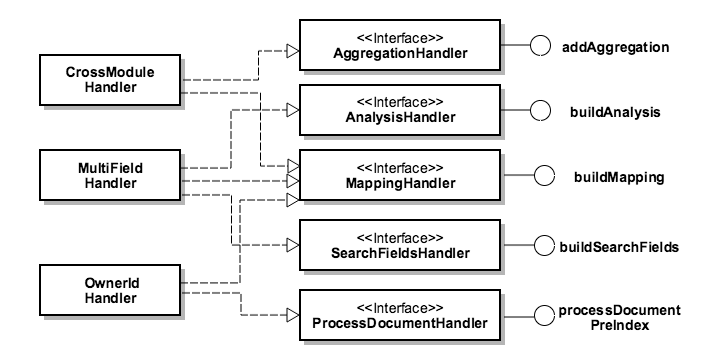
Global Search Provider
The provider supplies information to build analysis, mapping, query, etc. It is done by using handlers. Currently, there are two providers in the system: global search and visibility. To extend the functionalities, new providers and handlers may be added.
The following figure shows the existing handler interfaces and some of the handlers implementing them.
Query Builder
The Query builder composes the query string for search. A structure of a typical multi-match query is shown as follows:
{
"query": {
"filtered": {
"query": {
"bool": {
"must": [{
"bool": {
"should": [{
"multi_match": {
"type": "cross_fields",
"query": "test",
"fields": [
"Cases__name.gs_string^1.53",
"Cases__name.gs_string_wildcard^0.69",
"Cases__description.gs_string^0.66",
"Cases__description.gs_text_wildcard^0.23",
"Bugs__name.gs_string^1.51",
"Bugs__name.gs_string_wildcard^0.68",
"Bugs__description.gs_string^0.68",
"Bugs__description.gs_text_wildcard^0.24"
],
"tie_breaker": 1
}
}]
}
},
{
"bool": {
"should": [{
"multi_match": {
"type": "cross_fields",
"query": "query",
"fields": [
"Cases__name.gs_string^1.53",
"Cases__name.gs_string_wildcard^0.69",
"Cases__description.gs_string^0.66",
"Cases__description.gs_text_wildcard^0.23",
"Bugs__name.gs_string^1.51",
"Bugs__name.gs_string_wildcard^0.68",
"Bugs__description.gs_string^0.68",
"Bugs__description.gs_text_wildcard^0.24"
],
"tie_breaker": 1
}
}]
}
}]
}
},
"filter": {
"bool": {
"must": [{
"bool": {
"should": [{
"bool": {
"must": [{
"term": {
"_type": "Bugs"
}
}]
}
},
{
"bool": {
"must": [{
"term": {
"_type": "Cases"
}
}]
}
}]
}
}]
}
}
}
},
"highlight": {
"pre_tags": [
"<strong>"
],
"post_tags": [
"<\/strong>"
],
"require_field_match": 1,
"number_of_fragments": 3,
"fragment_size": 255,
"encoder": "html",
"order": "score",
"fields": {
"*.gs_string": {
"type": "plain",
"force_source": false
},
"*.gs_string_exact": {
"type": "plain",
"force_source": false
},
"*.gs_string_html": {
"type": "plain",
"force_source": false
},
"*.gs_string_wildcard": {
"type": "plain",
"force_source": false
},
"*.gs_text_wildcard": {
"type": "plain",
"force_source": false
},
"*.gs_phone_wildcard": {
"type": "plain",
"force_source": false
},
"*.gs_email": {
"type": "plain",
"force_source": false,
"number_of_fragments": 0
},
"*.gs_email_wildcard": {
"type": "plain",
"force_source": false,
"number_of_fragments": 0
}
}
}
}
Figure 7: Multi-match query with aggregations.
A query may include multiple filters, post filters, queries, and settings, which can get complicated sometimes. To add new queries, we recommend adding new classes implementing QueryInterface, instead of modifying Query Builder or even calling Elastica APIs directly.
ACL
ACL control is done in the Query Builder. The search fields are filtered based on their ACL access levels when being added to the query string in a specific query. For instance, MultiMatchQuery used for global search may include the following filterings:
- If a field is owner read (i.e.,
SugarACL::ACL_OWNER_READ_WRITE), it will be added to a sub-query with a filter of ownerId. - If a field is not owner read, its access level must not equal to
SugarACL::ACL_NO_ACCESS, in order to be added as one of the search fields in the query.
The corresponding function is MultiMatchQuery.php::isFieldAccessible(). Potentially this function can be shared by different queries that require ACL control.
Visibility
The visibility model is applied when building the query too. It is done by adding filters built by individual visibility strategies, defined in ./data/visibility/ directory. These strategies implement StrategyInterface including:
- building analysis,
- building mapping,
- processing document before being indexed,
- getting bean index fields,
- adding visibility filters.
The functions are similar to the global search provider's handler interfaces. The query builder only uses adding the visibility filters, while others provide information to Analysis builder, Mapping Manager, Indexer, etc. Hence the visibility provider is separated as an independent provider in the framework.