Sugar On-Site Sizing Guide
Overview
Sugar is a flexible and highly scalable application that supports a variety of hosting options including cloud hosting on our servers, hosting on a partner's server, hosting your instance yourself as an on-site deployment, or deploying on any existing public and private cloud option such as Amazon EC2 or IBM Softlayer. We collectively refer to all hosting options outside of Sugar's cloud hosting service as "on-site" installations. If you are considering an on-site installation, this guide will help you determine the server and storage requirements needed to satisfy performance needs of the application's end users.
Scope
This document provides a methodology and a set of reference data to assist with system resource and budgetary estimates. It is intended to serve as a best-practice guide for those planning a small- to medium-sized Sugar deployment. For assistance with on-site hardware sizing for an enterprise-scale deployment of more than 1,000 users, please contact your Customer Success Manager, for subscriptions purchased directly from Sugar, or your partner, for subscriptions purchased through a partner, for assistance identifying a resource to assist with a custom sizing effort. Please note that this document does not provide a set of benchmarks nor is it intended to serve as an operational guide to running Sugar.
Sugar Sizing-Estimation Process
Shown below is a diagram of the Sugar sizing-estimation process. It is not the only method for sizing a Sugar deployment, but it should provide useful insight and guidance.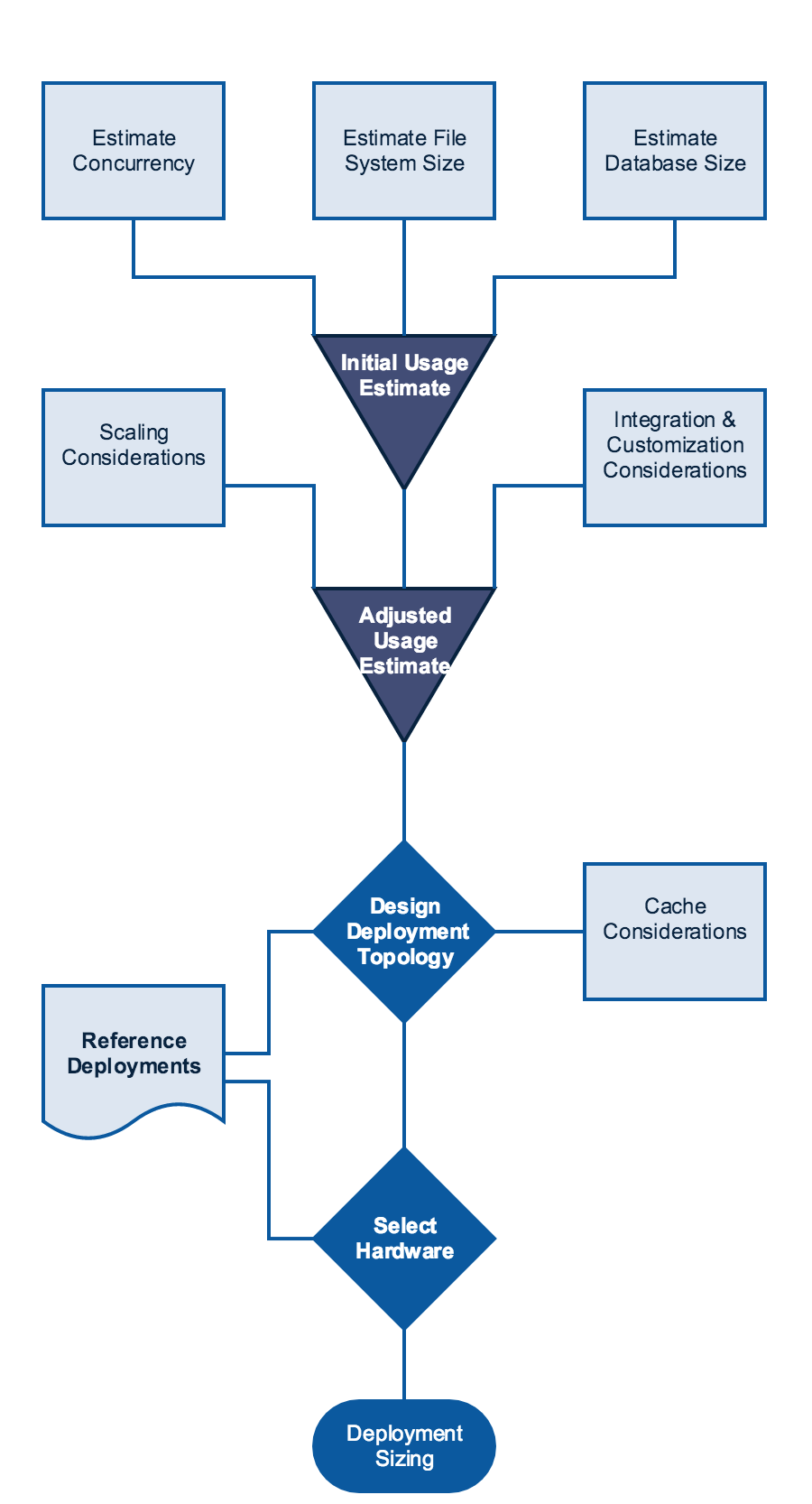
The following sections describe each step of the Sugar sizing-estimation process diagram, presented in their recommended order of execution:
- Estimate user concurrency and throughput
- Estimate the file system size
- Estimate the database size
- Create an initial, overall estimate
- Create an adjusted estimate based on scalability and integration and customization considerations
- Design a deployment topology using the adjusted estimate, cache considerations, and reference deployments
- Select the appropriate hardware based on the deployment topology and reference deployments
Estimating User Concurrency and Throughput
In most use-case scenarios, the number of expected concurrent users is far less than the number of named users of the Sugar system. A scenario in which all of the named users are simultaneously accessing the system is extremely rare. Normally, a globally distributed organization with users spread out all over the world experience about ⅓ of its named users online at any time during their individual 8-hour work days.
Concurrency typically ranges from 10% to 50+% for CRM deployments. Traditional Sales Force Automation (SFA) tends to have lower concurrency (around 10%). However, these users tend to run more reports, which is an expensive operation. Concurrency for busy call centers can exceed 60%. This value could be much higher or much lower depending on the planned usage scenario. Understanding your particular set of business cases is essential to estimate user concurrency properly.
For the reference deployments in this article, we apply a middle-ground concurrency estimate of 25%. For example, a deployment supporting 1,000 named Sugar users would serve 250 concurrent users.
The user concurrency percentage should increase as user adoption increases. Also, consider that as adoption increases, so too will the number of different clients (SugarCRM mobile app, Plug-ins, etc.) that are connecting to Sugar. Each of these clients may have different usage patterns. As an example, a SugarCRM mobile app user tends to put a lower load on the server with fewer and smaller requests made because that particular client tends to load fewer data per request. However, mobile users that make significant use of offline synchronization may increase the server load due to the increased number of records being pulled down into the device's local storage each time the user connects.
To calculate an estimated throughput for these users, estimate the number of requests a user will make per minute. This value is highly dependent upon actual planned-usage scenarios. So, again, fully understanding your business cases is essential to aligning your sizing estimates with actual demand.
An example of a simplistic throughput scenario assumes that record 'read' events could happen every few seconds, with 'write' operations happening every few minutes. For the reference deployments here, we assume a user would perform a new request every 10 seconds and, of these actions, 15% would be 'writes.'
As a more concrete example, one of the largest global Sugar deployments has 40,000+ named users. The deployment will average 3,000 requests every minute from 800 unique users. This scenario translates into 50 requests per second and an average of 3.75 requests per user, per minute.
In reality, however, users are not robots: they pause, they take breaks, and they have 9 am forecast calls, where 5 minutes beforehand, everyone runs the same report. Some users may even have a habit of opening many browser tabs all at once. Thus, it is also important to take into consideration irregular variations in user activity so as to fine-tune your load estimations.
Estimating the Size of Your File System
The Sugar application ordinarily runs out of a ./cache/ directory that gets built (and rebuilt as needed) during runtime. So, the size of the Sugar application increases a fixed amount during use. Under normal conditions, the size of the application should remain under 1 gigabyte.
Sugar also stores documents and file attachments on the server's possessive file system under the ./upload/ directory. The directory grows significantly based on the number and types of files that users upload to the Sugar instance from, for example, the Documents module, or file attachments in the Notes module. Some particularly storage-intensive file types include media files and, often, email attachments, which greatly increase storage requirements over time. Regular maintenance activities such as removing or archiving old files can help reduce file-system storage requirements.
Estimating Database Size
When sizing a database, consider that the size of each record stored in Sugar varies. You must take the time to understand these record types and the general quantity of each that you expect to store on the server. This is the most important factor in the sizing-estimation process.
Another consideration is the fact that Sugar stores record relationships in join tables. A pre-deployment assessment of the data to be imported into the system can ensure that the proper storage is provisioned. Be certain to allow for ongoing estimates of usage. The size of the database increases over time and will rarely (if ever) decrease in size unless aggressive archiving or maintenance strategies are put in place.
Periodically purging deleted records is a simple maintenance activity that any administrator can complete. When a user deletes a record, Sugar performs a 'soft' delete, which prevents the record from appearing in the application but retains the record data in the database as a precaution against accidental deletes. Using Sugar's Prune Database scheduled job, the administrator can schedule monthly purge activities to remove deleted records from the database permanently. For more information about Sugar's scheduled jobs, please refer to the Schedulers documentation.
Scaling Considerations
As your user base grows, the ability to handle higher throughput and an increased data load must grow, too. The following sections suggest ways to manage your organization's resources appropriately so the database can grow proportionally with demand.
Sugar Server Horizontal Scaling
The Sugar server is a PHP application, which excels at scaling horizontally. Therefore, building a shared hosting environment for Sugar is a common and cost-effective solution.
As an example, an environment designed to handle 1,000 named users of Sugar could theoretically be used to deploy 10 Sugar instances with 100 named users each or one instance with 1,000 named users. Keep in mind, though, that each of these deployments would be tuned very differently.
As a PHP application, you have some choices available to you on the PHP Server API (SAPI) that your web server could use. For example, PHP-FPM, FastCGI, or Apache. We have not seen major differences in performance between one SAPI and another, but your experience may vary.
Planning for Future Growth
A successful CRM deployment is going to grow over time, so it is important to plan and budget for this up front. It is common to include extra headroom in an initial deployment of Sugar. It is also important to know how and when to deploy extra capacity. A common growth model is to plan for 10% to 20% year-over-year growth.
In reality, growth is not going to be linear. Growth is often driven by adoption of new features or modules. For example, a Contact Management solution may grow to include sales force automation, marketing automation, and support case management. Adoption of these new features will cause the growth rate to spike as new departments start using the CRM. As a result, your deployment could easily double in size every couple of years.
Common Bottlenecks
Database and Input/Output (I/O) performance commonly create a bottleneck in Sugar deployments. When in doubt, plan for extra capacity around the database and I/O speed.
Regardless of the selected database platform, we strongly recommend that you consult a database administrator (DBA) with performance tuning expertise to ensure the database server is properly configured to adequately handle your workload.
Sugar Enterprise includes a feature that allows expensive, read-only database operations (e.g., reports and queries that populate list views) to run against a secondary database. Plan to use this feature for larger Sugar deployments or those that will be using the Reports module extensively. For more information on secondary databases, refer to the Advanced Configuration Options documentation.
Sugar's application I/O performance benefits when used with Solid State Drives (SSDs) because Sugar relies on many file reads and writes - especially against the database when rebuilding caches. At a minimum, it is best practice to deploy Sugar's database servers and ./cache/ directory on SSDs.
Integration and Customization Considerations
Sugar is not usually deployed straight out of the box and into isolation; Sugar can be integrated or customized using a variety of methods. An examination of these patterns is outside the scope of this document, but it is important to understand the expected loads that integrations or customizations create on the Sugar application and plan accordingly.
Integrations
There are two common types of integrations: real-time integrations that push and pull data into the Sugar application using one of the supported web services APIs, and batch processing that occurs at scheduled intervals (for example, every night) and tend to be heavier and move a lot more data.
Real-time integrations effectively increase the number of transactions (throughput) that the system experiences, especially if they involve reads or writes of data in the Sugar database. A chatty real-time integration could require an additional web server dedicated to API requests or additional database server capacity to keep performance under control. Real usage patterns normally drive a real-time integration, whereby specific user actions trigger the integration. The performance of real-time integration can also have an impact on these integrated systems due to latency, increased load, etc.
Batch processing jobs can create a tremendous load on the Sugar database. Rather than trying to plan extra capacity to handle these during peak usage times, it is better to plan on moving these workloads to off-peak hours such as during the night or, when this is not possible, dividing them into smaller chunks of work that can run throughout the day.
If these jobs utilize the Sugar Job Queue, then it may make sense to deploy a dedicated web server for running cron.
Customizations
Sugar is extremely flexible, but there are certain kinds of customizations that make running a high-performance Sugar instance difficult to do. For example, adding many subpanels to a record view increases server impact when users load the record view because a separate SQL query populates each subpanel. Expect a similar impact from displaying too many fields in commonly used list views or adding fields without the appropriate database indexes. Displaying these fields may require additional JOINs that impact response time and increase the load on the database.
Finally, remember that poorly performing JavaScript customizations can affect the browser performance (and ultimately the end-user experience) that no amount of server capacity can address.
Cache Considerations
There are a variety of cache layers in a Sugar deployment. Each cache option has different costs and benefits and may require some modifications to your final, deployed architecture.
PHP Session Storage
By default, PHP session data is stored on the file system. If your deployment involves more than a single web server, it is best to explore other PHP session storage options.
For our reference deployments, we used a Redis server to manage PHP session storage, but other popular options exist such as Memcached.
PHP Opcode Cache (PHP Accelerators)
Be sure to deploy Sugar with some form of opcode cache. We recommend using Zend OpCache. Many PHP distributions include APC, which is another common option. For Windows environments, WinCache is a popular choice. For more information about cache options, please refer to the Knowledge Base article, Improving On-Site Performance With PHP Caching.
SugarCache (External cache)
Sugar has a built-in cache interface for storing application data that can also be configured to use a variety of storage mechanisms. By default, Sugar can be configured to use the file system or APC cache without deploying additional hardware. Sugar supports Redis and Memcached as external cache providers. We recommend deploying a dedicated external cache for improved performance.
Designing a Deployment Topology
It is possible to run the entire Sugar application stack on a single machine, but this sort of deployment is difficult to scale up and lacks high availability or redundancy.
As deployment scales up, add load-balanced database servers and an Elasticsearch cluster first. It is advised to set up at least a three-node ES cluster for production systems, primarily for fault tolerance and secondarily for performance distribution. The odd number of primary nodes in the Elasticsearch cluster is to avoid a split brain problem. When using multiple web servers, add an external PHP-session storage mechanism, too.
If there are business continuity and high-availability requirements, then plan for additional backup servers, as well.
If the size of your deployment is similar to one of the reference deployments listed in this document, start with one of those deployments as your guide. Then modify it based on your specific usage estimates and additional configuration considerations, such as which caching mechanisms to use. Also, adjust the estimates based on your personal knowledge and experience. The reference deployments listed in this document are minimum deployments; in practice, your production deployment will require more resources than we specify here.
Overall, we recommend that you carefully identify all the logical components of your deployment. List each relevant aspect of your deployment methodology so that you can produce a set of reference data comparable to the reference deployments listed in this document.
Selecting Hardware
Once you've determined your system topology, you can begin to consider your hardware provisioning for the logical components of your system. Compare the hardware specifications applied to the reference deployments provided in this document to those you've applied in your personal experience. In this manner, determine how to procure the necessary resources and build a budget plan if necessary.
Sizing Example
We will take an example call center deployment of 1000 named users of Sugar Enterprise with a high expected concurrency of 60% (600 concurrent users). The deployment has a total of 14 million existing Task records plus many additional fields in the stock modules. The customer estimates a throughput of 40 requests per second (RPS) on this deployment. They also estimate that users would create or modify 10,000 Sugar records each day. We will also include headroom for a planned first-year expansion.
This estimate is roughly comparable to Profile C in the reference profiles, which has the same number of users (1,000). This call-center example, however, has double the expected traffic. The call-center deployment would also hit 40 RPS versus the 20 RPS in our reference deployment. We are putting aside the integration requirements. This example also illustrates a common high availability setup without single points of failure.
| Machines | CPU | RAM | Storage |
| 1 Web Load Balancer | 2 vCPU | 4 GB | |
| 2 Web Servers | 8 vCPU | 32 GB | |
| 2 Database Servers (Active-Passive) | 16 x 2.26GHz | 64GB | 6600 IOPS |
| 2 Session Servers (Redis) | 2 vCPU | 8 GB | |
| 1 Elasticsearch Load Balancer | 2 vCPU | 4 GB | |
| 3 Elasticsearch Servers | 2 vCPU | 16 GB | 1 TB local storage |
Notes:
- The two database servers could be replaced with a cluster of two or more database servers.
- Sugar Enterprise can be configured so the workload for list views and reports are executed against the shadow database in a two-database configuration, which greatly helps balance database resources.
- In some circumstances, the Redis servers could be co-located with the Web Servers.
- Elasticsearch recommends odd numbers of servers for performance reasons. This is why we go with three Elasticsearch servers instead of two.
- We also recommend enterprise-class Network Attached Storage for Sugar file storage in some scenarios.
Reference Deployment Sizings
SugarCRM's Performance Engineering team developed the following sizings for your reference. They set up the deployments on Amazon EC2 and maintained an Apdex score of 0.95, which translates into excellent user satisfaction. For your convenience, they also provide the EC2 instance types for each machine used in the configuration below.
Sugar Instance Configuration
These profiles were developed using uncustomized versions of Sugar Enterprise. The reference deployments do not use any integrations.
Heavy customizations or integrations can have an impact on Sugar performance. For more information, please refer to the Sugar Sizing-Estimation Process section of this page.
Amazon EC2 Optimizations
The following sections discuss optimizations that apply specifically to Sugar instances hosted on Amazon Web Services Elastic Compute Cloud.
EBS Initialization
It is best practice to initialize, or "pre-warm", the EBS disk for better performance. You should only pre-warm before performing system setup and before mounting storage. For more information on EBS Initialization, please refer to the Initializing Amazon EBS Volumes documentation on the AWS website.
IOPS Ratio & Disk Size
Input/Output of EBS speed varies depending on the size of the disk. A larger disk performs better, so we recommend using at least 16GB EBS volumes to provide acceptable disk performance.
Amazon RDS
Amazon offers a relational database service that provides access to common database engines in order to simplify deployments. The Amazon-based reference deployments in this article did not leverage RDS in order to provide a fixed hardware recommendation, but those deploying Sugar on Amazon EC2 should consider leveraging Amazon RDS. Visit the Amazon RDS product page for more information.
Deploying Sugar On-Site for Development and QA purposes
A full Sugar deployment can be deployed on a single laptop. However, If you are planning to deploy Sugar instances for limited development, demonstration, or QA purposes on dedicated hardware then use Profile A below as your guide.
Profile A: 3 Requests Per Second
This profile was designed around an approximate 20-user deployment with an estimated peak of 5 concurrent users, where each active user makes a request almost every second. It uses a single machine configuration, which is cost-effective and recommended for very small Sugar deployments or those used primarily for development or demonstration purposes. This instance is not customized.
Usage Load
| Factor | Estimate |
| Requests per second | 3.3 |
| Total users | 20 Users |
| Concurrent users | 5 (25%) |
| Delay between requests per user | 1 second (+/- 20%) |
| Write requests | 15% |
Deployment Topology
Not Applicable
Machine configuration
| Instance type | vCPU | RAM | Disks | OS |
| c3.large | 2 | 3.75GB | EBS Provisioned IOPS(480) 16GB |
Debian 8 |
Profile B: 6 Requests Per Second
This profile was designed around an approximate 250-user deployment with an expected peak of 60 concurrent users. This configuration was developed on a topology that uses load balanced database servers. This instance is not customized.
Usage Load
| Factor | Estimate |
| Requests per second | 6 |
| Total users | 250 Users |
| Concurrent users | 60 (24%) |
| Delay between requests per user | 10 seconds (+/- 10%) |
| Write requests | 15% |
Deployment Topology
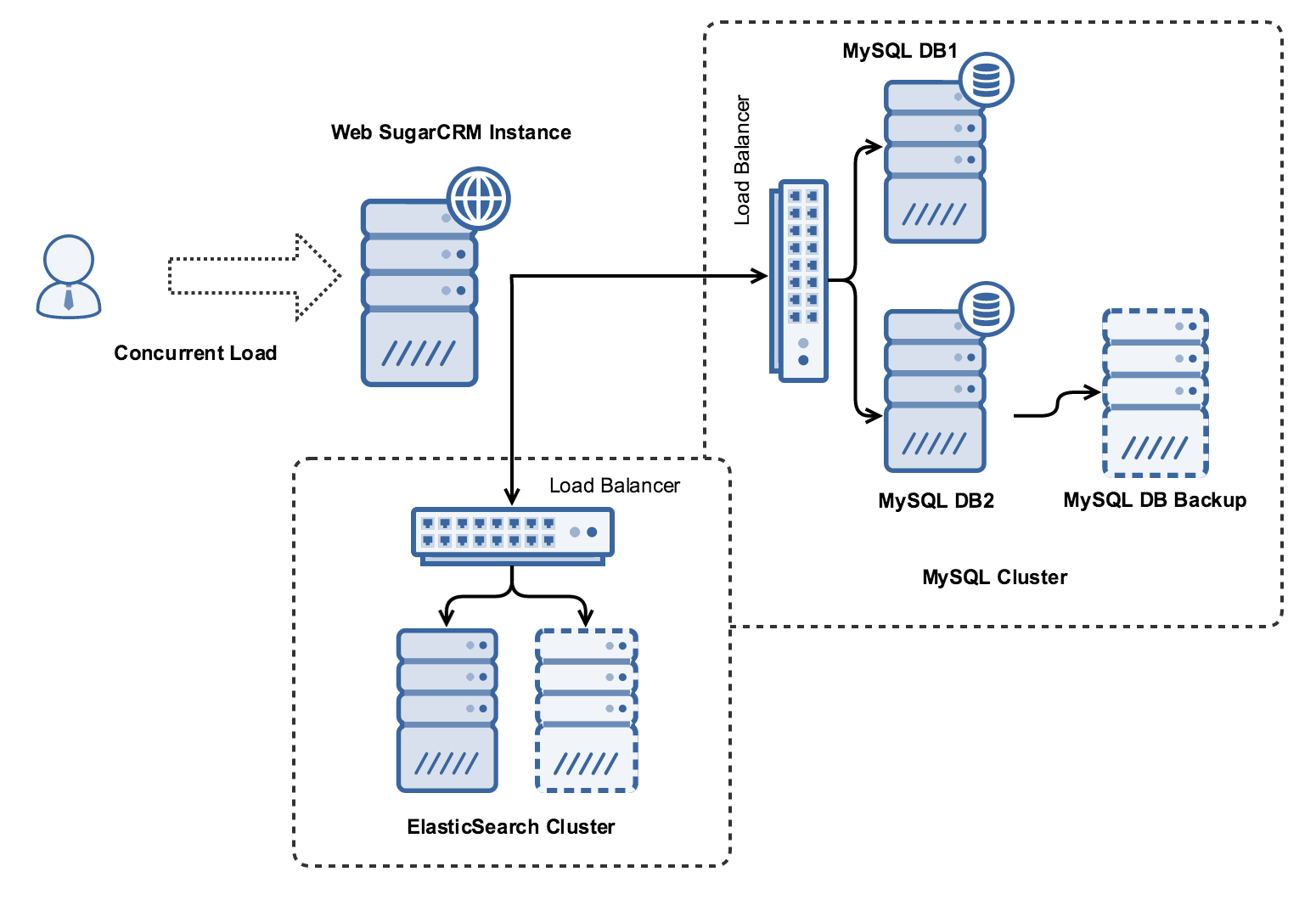
Machine Configurations
| Role | Instance Type | vCPU | RAM | Disks | Software | OS |
| Web | c3.xlarge | 4 | 7.5 | Apache + PHP | Debian 8 | |
| DB 1 | c3.xlarge | 4 | 7.5 | EBS Provisioned IOPS (1800) 60GB | MySQL | Debian 8 |
| DB 2 | c3.xlarge | 4 | 7.5 | EBS Provisioned IOPS (1800) 60GB | MySQL | Debian 8 |
| DB Backup | c3.xlarge | 4 | 7.5 | EBS Provisioned IOPS (1800) 60GB | MySQL | Debian 8 |
| Elastic Balancer | m3.medium | 1 | 3.75 | HA Proxy | Debian 8 | |
| Elasticsearch | m3.medium | 1 | 3.75 | Elasticsearch | Debian 8 | |
| Elasticsearch | m3.medium | 1 | 3.75 | Elasticsearch | Debian 8 | |
| DB Load balancer | m3.medium | 1 | 3.75 | HA Proxy | Debian 8 |
Profile C: 20 Requests Per Second
This profile was designed around an approximate 1000-user deployment with an expected peak of 250 concurrent users. This configuration was developed on a topology that ensures high availability via multiple load-balanced web servers, database clusters, and introduction of Redis for scalable PHP session storage. This instance is not customized.
Usage Load
| Factor | Estimate |
| Requests per second | 22 |
| Total users | 1,000 Users |
| Concurrent users | 250 (25%) |
| Delay between requests per user | 10 seconds (+/- 10%) |
| Write requests | 15% |
Deployment Topology
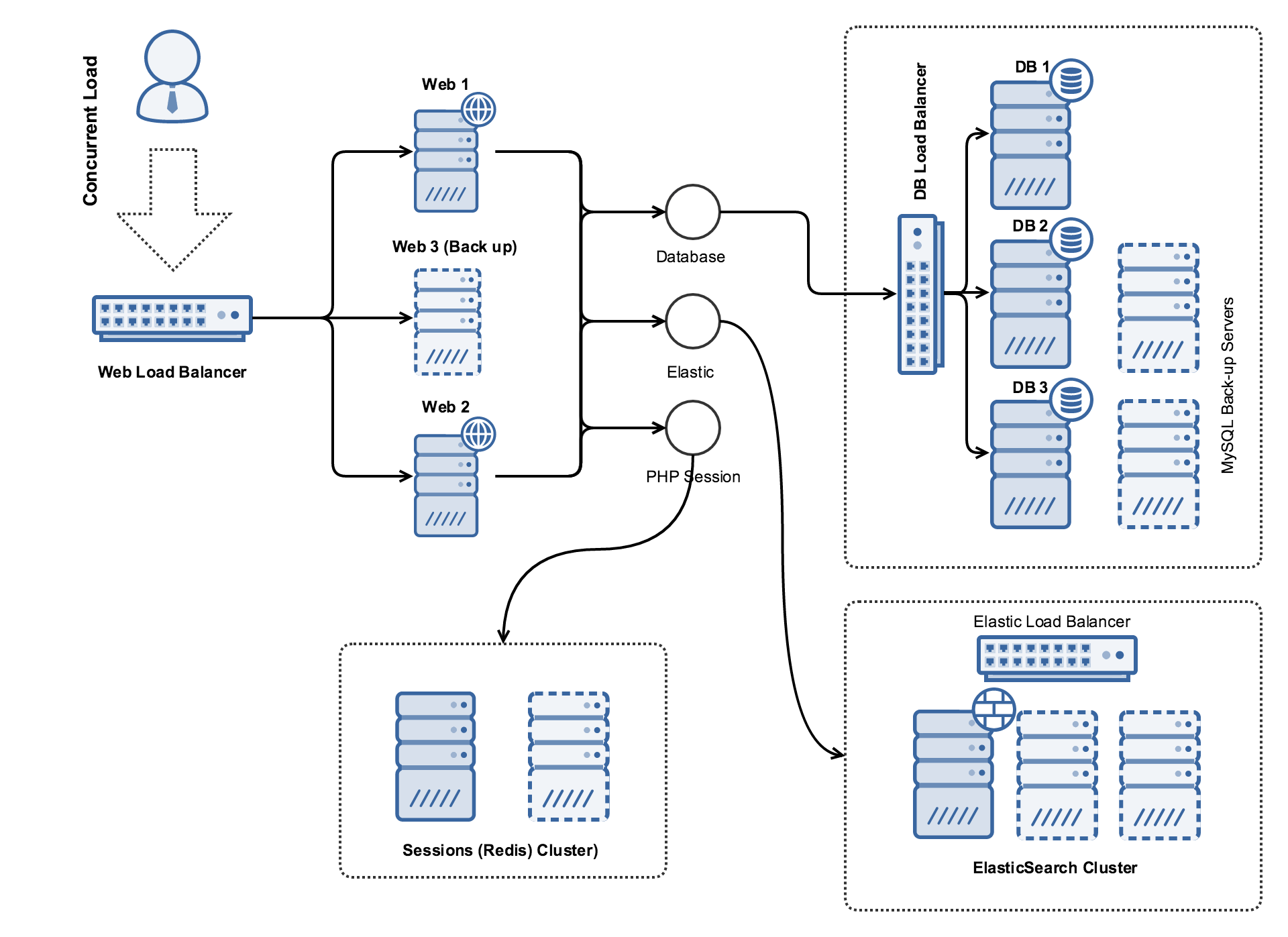
Machine Configurations
| Role | Instance Type | vCPU | RAM | Disks | Software | OS |
| Web LoadBalancer | c3.large | 2 | 3.75 | HA Proxy | Debian 8 | |
| Web 1 | c3.4xlarge | 16 | 30 | Apache + PHP | Debian 8 | |
| Web 2 | c3.4xlarge | 16 | 30 | Apache + PHP | Debian 8 | |
| Web 3 (back up) | c3.4xlarge | 16 | 30 | Apache + PHP | Debian 8 | |
| DB LoadBalancer | m3.medium | 1 | 3.75 | HA Proxy | Debian 8 | |
| DB 1 | c3.4xlarge | 16 | 30 | EBS Provisioned IOPS(6600 IOPS) 220G | MySQL Cluster | Debian 8 |
| DB 2 | c3.4xlarge | 16 | 30 | EBS Provisioned IOPS(6600 IOPS) 220G | MySQL Cluster | Debian 8 |
| DB 3 | c3.4xlarge | 16 | 30 | EBS Provisioned IOPS(6600 IOPS) 220G | MySQL Cluster | Debian 8 |
| DB 5 (back up 1) | c3.4xlarge | 16 | 30 | EBS Provisioned IOPS(6600 IOPS) 220G | MySQL Cluster | Debian 8 |
| DB 5 (back up 2) | c3.4xlarge | 16 | 30 | EBS Provisioned IOPS(6600 IOPS) 220G | MySQL Cluster | Debian 8 |
| Elasticsearch 1 | m3.medium | 1 | 3.75 | Elasticsearch | Debian 8 | |
| Elasticsearch 2 | m3.medium | 1 | 3.75 | Elasticsearch | Debian 8 | |
| Elasticsearch 3 | m3.medium | 1 | 3.75 | Elasticsearch | Debian 8 | |
| Elastic Load Balancer | m3.medium | 1 | 3.75 | HA Proxy | Debian 8 | |
| Session Storage 1 | c3.large | 2 | 3.75 | Redis | Debian 8 | |
| Session Storage 2 | c3.large | 2 | 3.75 | Redis | Debian 8 |
Microsoft SQL Server Deployments
Microsoft Windows and SQL Server tend to be greedier with their memory usage than Linux and MySQL. Our experience is that you should add up to 8GB of RAM on each system in a Linux and MySQL server setup for comparable sizing on a Windows and MS SQL Server environment.
Oracle or DB2 Deployments
Oracle and IBM DB2 are the most common choices for larger Sugar deployments with more than 1,000 named users. We are currently working to determine reference configurations for Oracle and DB2 databases and will update this guide with the reference data when our testing is complete.
Reference Deployment Testing Methodology
The following sections discuss the methods we used to test the reference deployments provided in this document.
Apdex
Apdex is an industry-standard measurement of user satisfaction for web application performance. Apdex scoring is based on time-threshold values where requests that exceed these selected thresholds will leave the user unsatisfied with the responsiveness of the application. The Apdex method converts a set of request-timing measurements into a number on a uniform scale from 0 to 1, where 0 means no users are satisfied and 1 means that all users are satisfied with performance.
For our calculations, we use a 2-second satisfaction threshold and a 4-second tolerable threshold. The reference profiles that we have developed maintain at least a 0.95 Apdex score based upon the given threshold values, which indicates near optimal user satisfaction.
Test Technology
For SugarCRM API testing, we use Apache JMeter to generate the load and Tidbit to generate the dataset for each reference profile. For front-end (Sidecar) testing, we are starting to utilize browser-based tests written in CucumberJS with SugarCRM's Seedbed testing framework. The front-end testing is still a work in progress.
Access to our JMeter testing framework and Sugar scenarios is available to Sugar customers and partners through our Sugar Developer Tools program. Please sign up for access to the sugarcrm/performance Github repository.
Test Profiles
In order to determine optimal configurations and have the ability to test Sugar on different stacks and data sizes, we separated our testing into different profiles based on the total number of users. We built these profiles based, in part, on our experience in hosting cloud customers. These test profiles were designed around uncustomized Sugar instances for a solid performance baseline.
For each profile, we started with a set number of total users. From that, we chose a peak concurrency of 25% for each profile which we used to reach an estimated number of requests per second (RPS) that the Sugar deployment would need to service for this given profile. Since RPS is the single biggest factor in performance, we label the profiles based on the number of concurrent users.
Finally, from the total number of users in each profile, we populated the database with an appropriate number of records that an organization of that size would produce.
Profile Definitions
| Type | Total Users | Concurrent Users (threads) | Planned RPS | DB size |
| 3 RPS Profile | 20 | 5 | 3.3 | 100 MB |
| 6 RPS Profile | 250 | 60 | 6 | ~ 5 GB |
| 20 RPS Profile | 1000 | 250 | 20 | ~ 60 GB |
Profile Databases
Below is listed the number of Sugar records used in each profile. These records also include realistic relationships. For example, Opportunities and Contacts are related to Accounts. This test data was generated using the Tidbit tool.
| Module | 3 RPS Profile | 6 RPS Profile | 20 RPS Profile |
| Teams | 4 | 50 | 200 |
| EmailAddresses | 12,000 | 600,000 | 2,400,000 |
| Accounts | 1,000 | 50,000 | 200,000 |
| Users | 20 | 250 | 1,000 |
| Quotes | 1,000 | 50,000 | 200,000 |
| ProductBundles | 2,000 | 100,000 | 400,000 |
| Products | 4,000 | 200,000 | 800,000 |
| Calls | 24,000 | 1,200,000 | 4,800,000 |
| Emails | 16,000 | 800,000 | 3,200,000 |
| Contacts | 4,000 | 200,000 | 800,000 |
| Leads | 4,000 | 200,000 | 800,000 |
| Opportunities | 2,000 | 100,000 | 400,000 |
| Cases | 4,000 | 200,000 | 800,000 |
| Bugs | 3,000 | 150,000 | 600,000 |
| Meetings | 8,000 | 400,000 | 1,600,000 |
| Tasks | 4,000 | 200,000 | 800,000 |
| Notes | 4,000 | 200,000 | 800,000 |
| Documents | 1,000 | 50,000 | 200,000 |
| Activity Per User | 6,500 | 6,500 | 6,500 |
| Activity | 1,300,000 | 16,250,000 | 65,000,000 |
| Total (with relationships) |
1,400,524 | 37,206,800 | 110,802,200 |
JMeter Systems
In addition to testing the configured Sugar deployment for each scenario, we deployed an additional system to drive the JMeter testing.
3 RPS Profile
| Role | CPU Cores | Memory | SSD Size | Components |
| Jmeter | 4 | 4 GB | Java, Apache Jmeter tests |
6 RPS Profile
| Role | CPU Cores | Memory | SSD Size | Components |
| Jmeter | 6 | 4 GB | Java, Apache Jmeter tests |
20 RPS Profile
| Role | CPU Cores | Memory | SSD Size | Components |
| Jmeter | 6 | 4 GB | Java, Apache Jmeter tests |
Appendix: Resources
The following resources provide additional information about the topics covered in this article.
Accessing Sugar Test Tools
You must be a current SugarCRM partner or customer to access certain Sugar Test Tools such as the JMeter scenarios described in this guide. Sugar Test Tools should be used with test or internal evaluation environments alone and should never be used with a production Sugar instance or any instance hosted on Sugar's cloud servers. These test tools are hosted on the SugarCRM organization on Github. For access to these private Github repositories, please fill out and submit a request. Once your request has been reviewed and approved, you will receive an invitation from Github to the SugarCRM organization that will grant you access to these repositories.
Amazon Instance Types
Detailed information and specifications for the various Amazon instance types listed in this guide can be found in the Amazon EC2 documentation.